
Nearly twelve years ago, Kraken began its pioneering mission to become one of the first and most successful digital asset exchanges. We started trading only four cryptocurrencies, but we now support over 220 assets on 67 blockchains, and over 700 markets.
We’ve grown quickly. Thanks to our product and engineering teams — including experts in blockchain technology, security, networking, infrastructure, and trading systems — we’ve been able to keep up with massive demand.
As the industry has matured and evolved, so has the size and nature of our client base. While we continue to serve individual investors and traders via our Kraken and Kraken Pro platforms, a growing part of our order flow arrives algorithmically via our API from professional and institutional clients. These include corporations, hedge funds, proprietary trading firms, prime brokers, fintechs, as well as other exchanges relying on Kraken’s deep liquidity.
Our trading systems have had to scale to meet these increased demands, particularly for those that heavily depend on speed, stability, and uptime in order to improve execution costs, manage market risk, and capitalize on trading opportunities. We achieved all of this without compromising on our number one priority — security.
Today, we’re delighted to highlight some of our recent efforts, successes, and results of that scaling.
The primacy of performance
We put significant emphasis on instrumenting code to watch and understand our system performance under heavy, real-world conditions. We also employ competitive benchmarking to confirm how we stack up over time. Let’s explore some of those results.
Speed and latency
We measure trading speed in the form of latency. Latency is the round-trip delay and we define it as the time between a trading request (e.g., add order) being sent by client systems and it being acknowledged by the exchange.
Unlike traditional exchanges, crypto venues are generally less geographically concentrated and don’t offer full colocation. In many cases, they are entirely cloud-based.
Latency-sensitive clients will deploy code wherever it is most physically proximate to the venue. Therefore, a fair comparison includes measuring latency from the region most relevant for that specific venue.
Latency will also vary between trading requests, even on a persistent connection between a single client and the exchange. This is due to both differences and variability in internet-based trading, as well as how the exchange is handling load. Therefore, we must discuss latencies in terms of percentiles rather than single figures. For example, P25 latency refers to the 25th-percentile latency. In other words, a P25 of 5ms means that 25% of all trading requests within a given sampling time frame had a latency of 5ms or better.
Here you see Kraken’s best path P25 latency versus some of our top competitors in different regions, normalized for location, during a baseline measurement last month.
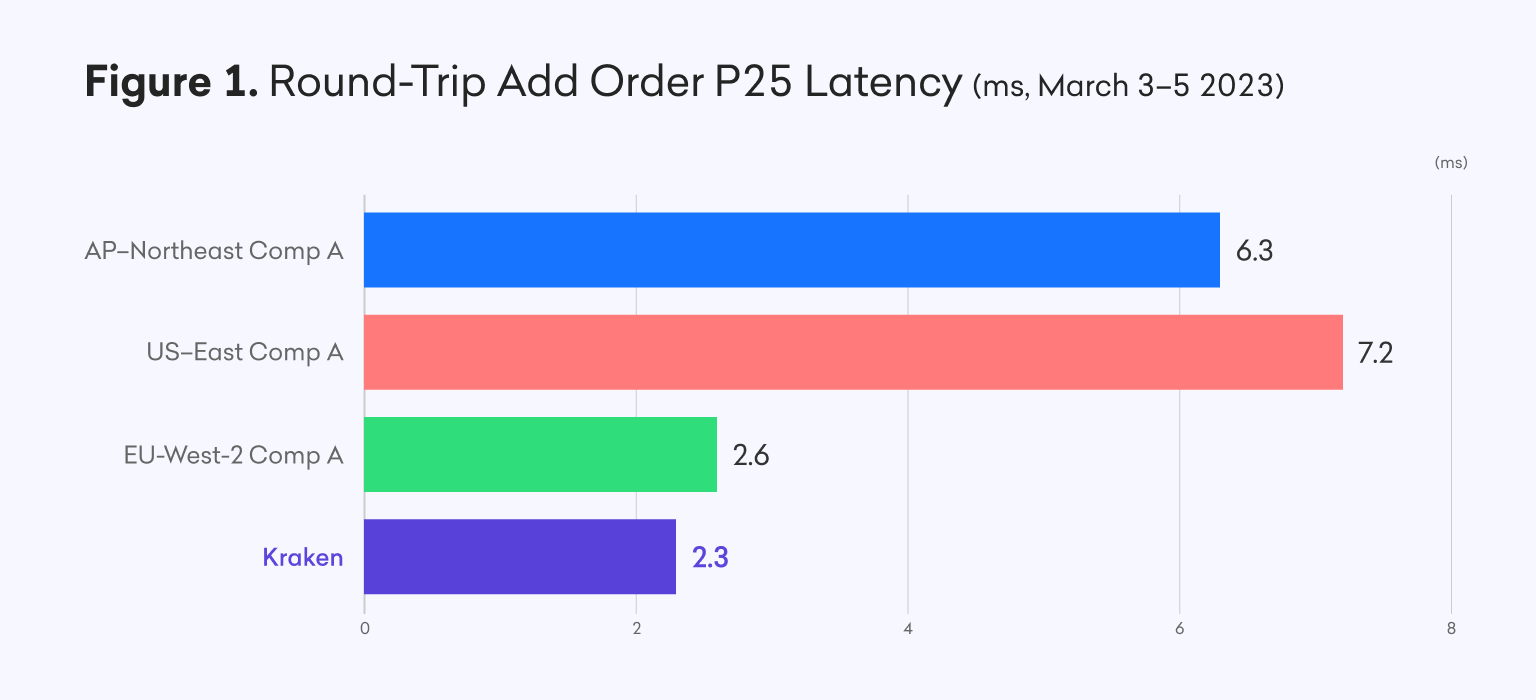
Our baseline round-trip latency of about 2.5ms represents over a 97% improvement vs. Q1 2021.
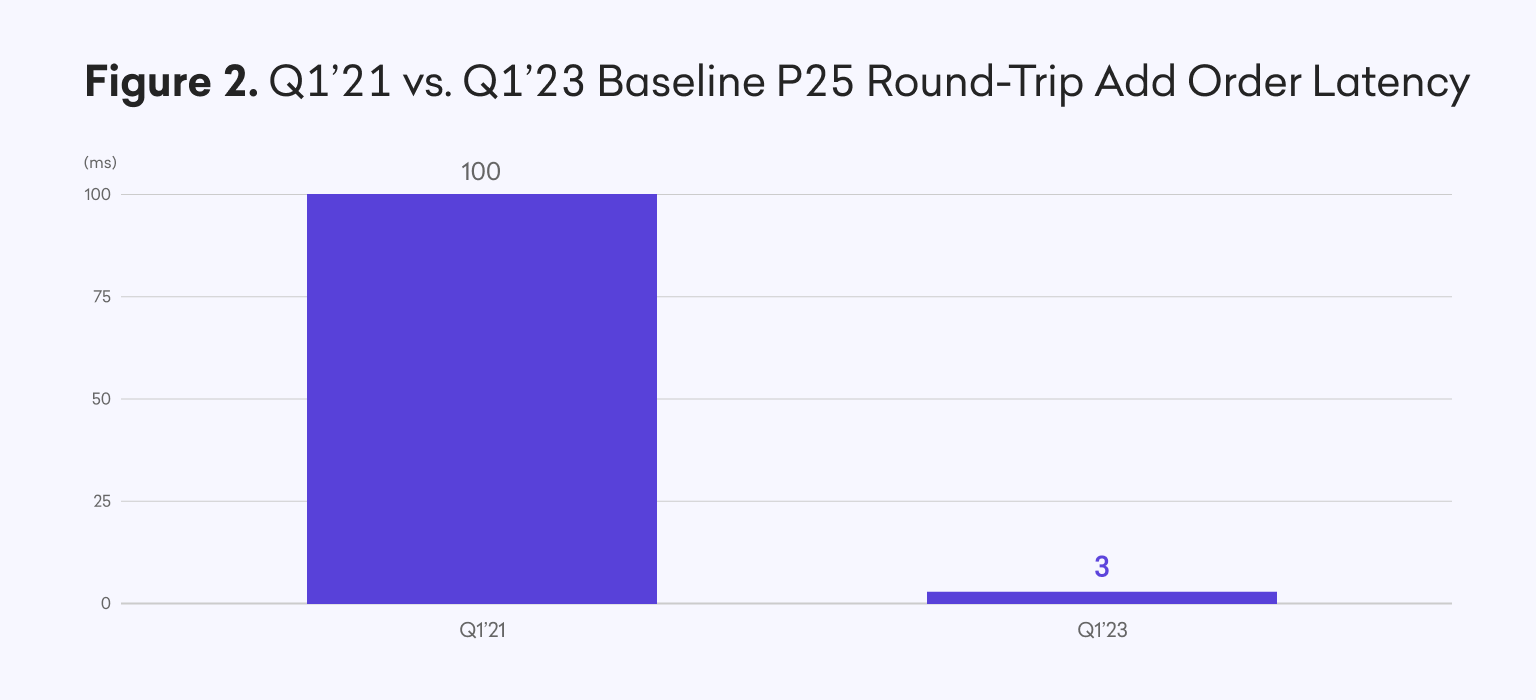
Stability
As mentioned before, real-world performance under heavy load is as important, if not more important, than best case performance and absolute latency figures.
Improving execution cost, reducing slippage, and managing market risk depends on minimizing the variability of latency between each trading request. We call this variability jitter, and we measure the difference between different latency percentile figures for the same sampling time frame.
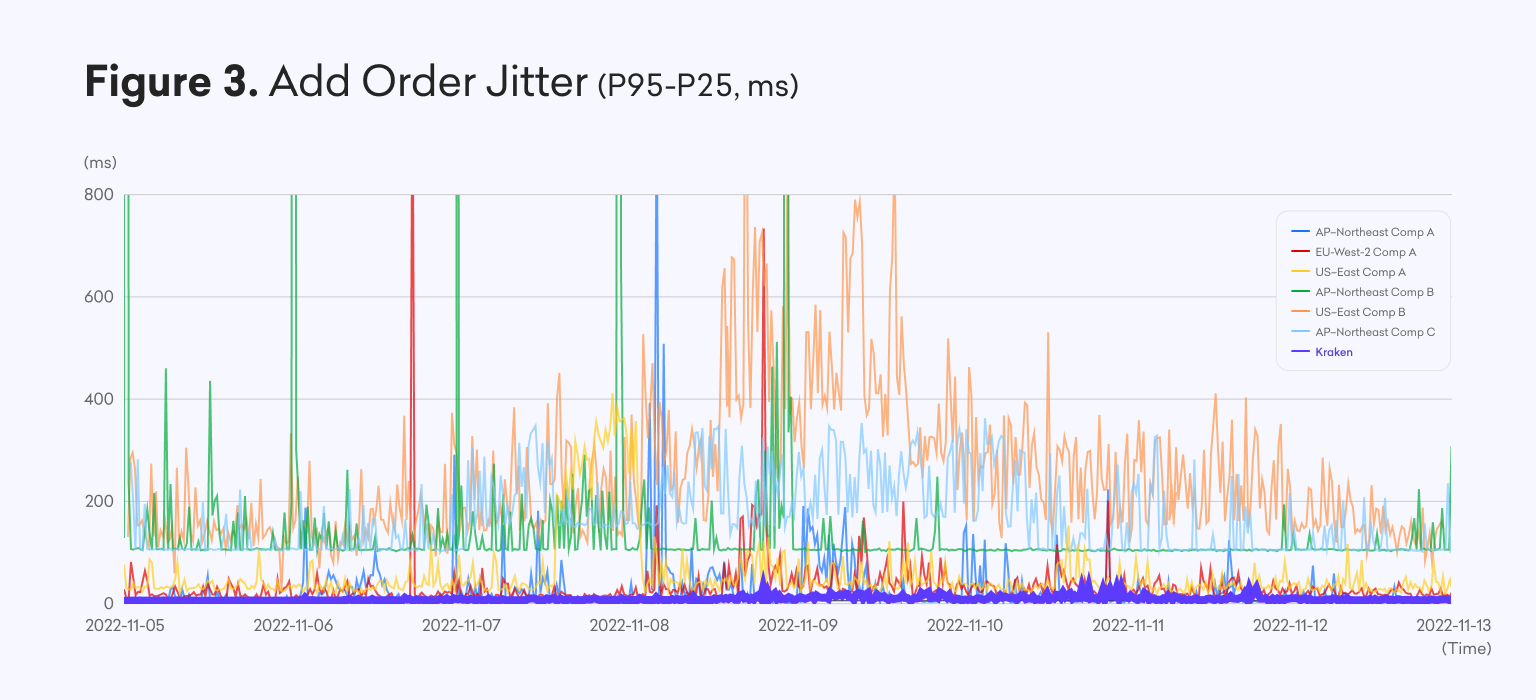
By measuring jitter with P25 and P95 latencies, we can capture a significant range of performance and observed behavior over time. For example, we measured how our jitter stacked up with a broader set of top competitors during the week of 5-12 November 2022, a time when market volatility was acute due to the distress and ultimate shutdown of FTX.
Here you can see how our trading infrastructure behaved exceptionally well, despite the dramatically increased volatility and load. At no point during the week did this jitter exceed 30ms. Meanwhile, for many other exchanges, it regularly reached several hundred milliseconds, or requests timed out entirely as indicated by the vertical spikes.
Throughput
Throughput reflects the number of successful trading requests (add order, cancel order, edit order, etc.) handled by an exchange in a given amount of time.
Similar to latency, we discuss throughput in either theoretical or observed terms.
Observed throughput is more relevant since it reflects many interrelated factors including rate limits. We set these limits to prevent DDoS attacks and keep traffic comfortably within theoretical limits. Size of the client base, general market demand, order flow (which is impacted heavily by price volatility and trading activity elsewhere), and performance under load (since beyond a certain level of service degradation, clients would start throttling their own requests) all affect these limits.
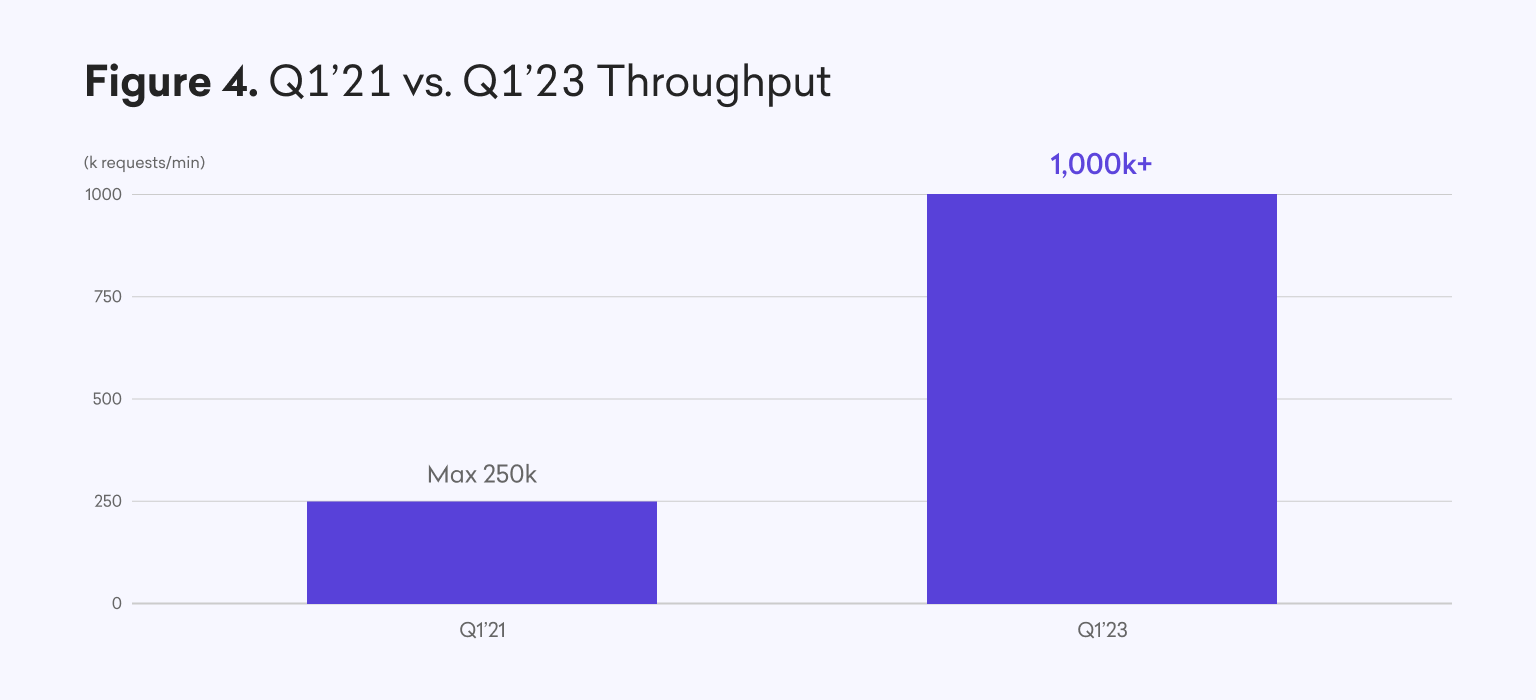
Here we’ve illustrated the over 4x improvement in our maximum observed throughput between Q1 2021 and Q1 2023. This change is a move from 250k requests/min to over 1mm requests/min, and there is significant headroom left between this level and our dramatically improved theoretical maximum throughput.
Uptime
This year, we made efforts to minimize downtime due to planned maintenance, reduce the frequency and impact of unscheduled downtime, and increase the velocity of feature updates and performance improvements without negatively impacting uptime.
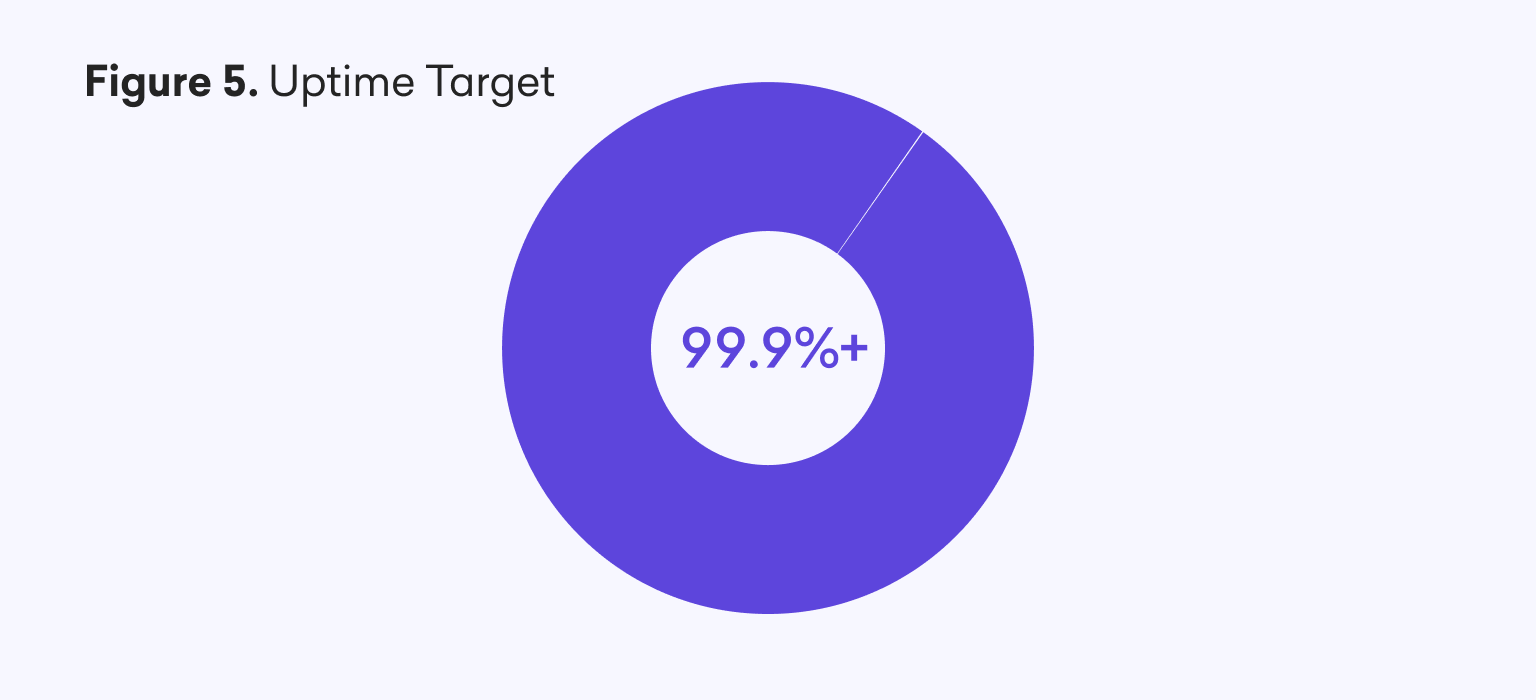
These changes included both technical and operational improvements, such as an increasingly mature and large operational resilience team which operates 24/7.
While uptime for our worst month in 2021 was close to 99%, these improvements have allowed us to set increasingly aggressive error budgets and a trading uptime target of 99.9+%.
Efforts
Blue/green and rolling deployments
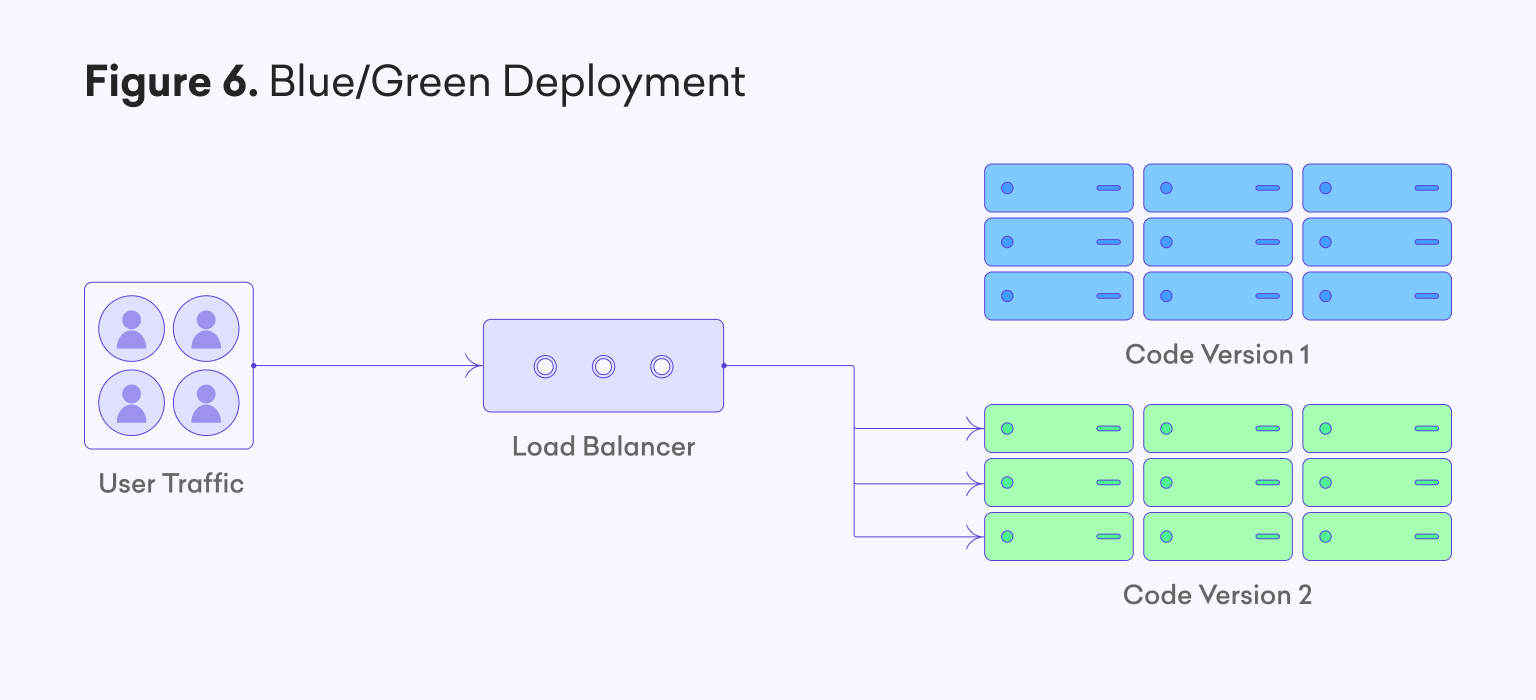
We have made increasing use of a blue/green deployment strategy across our API gateways and many internal services. You can see a very simplified illustration of this is highlighted in Figure 6. By operating multiple fully-fledged code stacks in parallel, we can deploy features without disturbing the main stack which is currently receiving client traffic. Afterward, traffic can be re-routed to the new stack, leading to a zero-impact deployment, or a very quick rollback procedure should anything go wrong. Furthermore, for our many services which operate multiple instances for purposes of load balancing, updates to these instances happen on a rolling basis rather than all-or-none. These approaches now allow us to conduct zero-impact, and more frequent updates, to the vast majority of our tech stack.
Infrastructure as Code
Kraken heavily leverages Infrastructure as Code (IaC) with Terraform and Nomad, in large part to guarantee consistency of all code deployments as well as repeatability. We automate our Terraform repositories with continuous integration and continuous delivery so we can roll changes out quickly and reliably. For the past two years, we have deployed new infrastructure using IaC and nearly all of our infrastructure today uses this pattern. This move was a major milestone and we leverage IaC for both cloud-based and on-premise applications.
Connectivity and networking
We leverage private connectivity between AWS and our on-premise data centers. This connectivity allows Kraken to guarantee we have the lowest possible latency, highest possible security, and redundant paths to make sure we can reach out to AWS at all times. Recent networking and routing improvements have enabled a significant part of the baseline round-trip trading latency reduction highlighted above.
Instrumentation and telemetry
Fine-grained and accurate logging, metrics, and request tracing have allowed us to quickly identify, diagnose, and resolve any unexpected bottlenecks and performance issues in real-time. Beyond this telemetry and our own competitive monitoring, we’ve also recently updated our API latency and uptime metrics on status.kraken.com with external monitor deployments to, in general, more accurately reflect these numbers as experienced by clients.
Optimized API deployments
At any given moment, our APIs and trading stack support tens of thousands of connections trading algorithmically through our Websockets or REST APIs. Hundreds of thousands more connections come from our UI platforms, including our new high-performance Kraken Pro platform. While these platforms reap many of the same core trading infrastructure benefits described in this post, the workloads are fundamentally different and have different requirements. Bespoke API deployments to support our UI platforms, with specific data feeds, compression, throttling, aggregation, etc have allowed us to further improve speed and reduce wasted bandwidth, and therefore increase overall client capacity.
Core code improvements
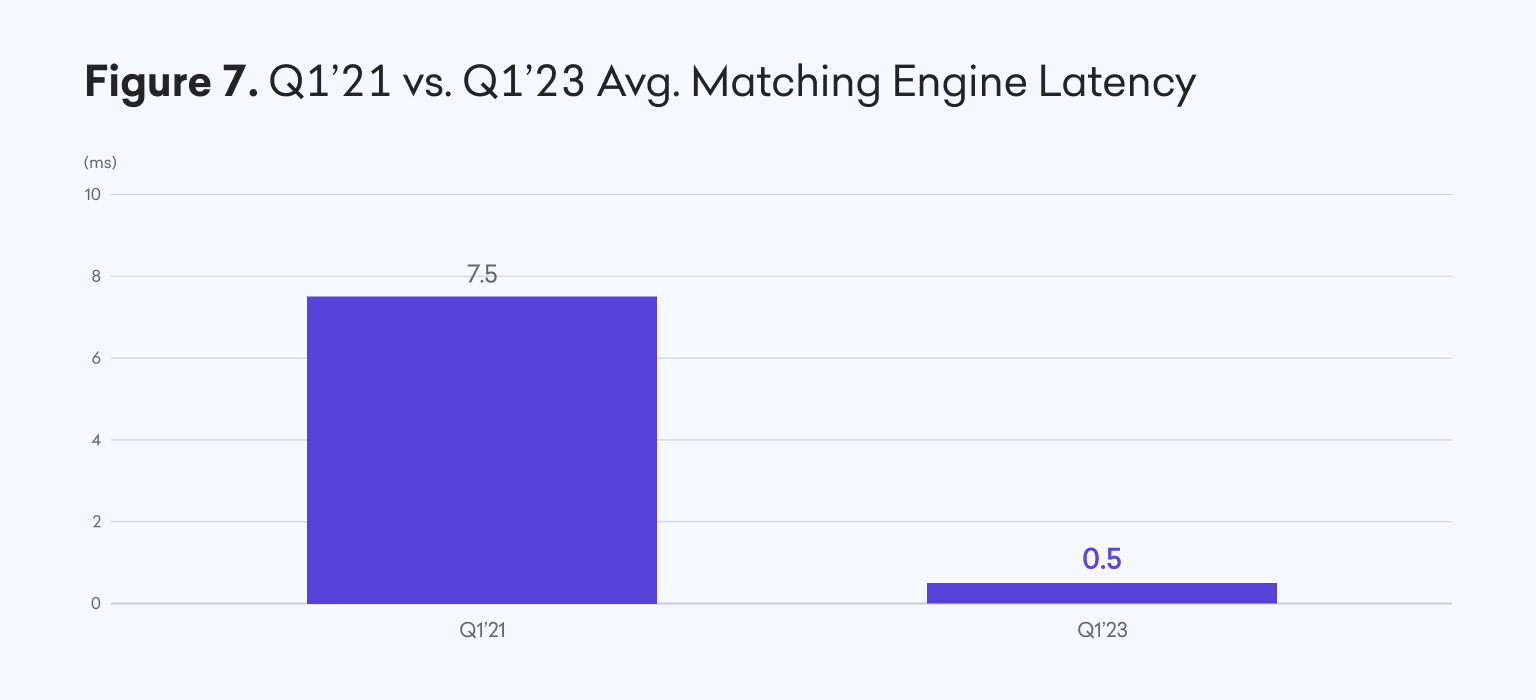
We have made a range of further, dramatic improvements across the stack through re-engineering core services in Rust and C++. These changes make increased use of asynchronous messaging and data persistence where possible and help us build robust performance profiling into more of our CI/CD pipelines. They also lets us employ best known methods for static and dynamic code analysis. Several of these improvements have culminated in the matching engine’s average latency dropping from milliseconds to microseconds. This a more than 90% improvement vs two years prior, while supporting over 4x the throughput.
What’s next?
Native FIX API
We’ll also soon be launching our native FIX API for spot market data and trading. FIX, which stands for Financial Information Exchange, is a powerful and comprehensive but flexible industry-standard API that many institutions use for trading equities, FX, and fixed income at a massive scale. It’s a trusted and battle-tested protocol, with broad third party software and open source support, making it easier and quicker for institutions to integrate with Kraken and begin trading.
Kraken’s native FIX API also comes with architectural nuances and benefits relative to our Websockets and REST APIs, including session-based cancel-on-disconnect, guaranteed in-order message delivery, session recovery, and replay. Our FIX API is currently in beta testing — reach out if you’d like to help kick the tires!
Zero-downtime matching engine deployments
We’ve made significant inroads on the frequency of zero-impact deployments of API gateways and various backend services (authentication, audit, telemetry, etc.). Material updates to our matching engine, though, still require scheduling maintenance and brief downtime, which we carry out roughly biweekly.
However, our team underwent a significant effort to re-engineer some of our internal messaging systems with multicast technology, making use of Aeron, an extremely performant and robust suite of tools for fault-tolerant high availability systems. The result of this will be zero-downtime planned deployments across the trading stack, available later in 2023.
Need help? Reach out
Please reach out to our account management and institutional sales teams using the email address [email protected] to learn more about any of these updates, to discuss how to optimize your trading connectivity, or to beta test forthcoming features like our FIX API.
Need more proof? Keep an eye out and subscribe to updates on status.kraken.com for any planned maintenance, service information and latency and uptime statistics.
Like this:
Like Loading…
Source: https://blog.kraken.com/post/17936/performance-at-kraken/

