
DeepSeek, the Chinese AI lab that recently upended industry assumptions about sector development costs, has released a new family of open-source multimodal AI models that reportedly outperform OpenAI’s DALL-E 3 on key benchmarks.
Dubbed Janus Pro, the model ranges from 1 billion (extremely small) to 7 billion parameters (near the size of SD 3.5L) and is available for immediate download on machine learning and data science hub Huggingface.
The largest version, Janus Pro 7B, beats not only OpenAI’s DALL-E 3 but also other leading models like PixArt-alpha, Emu3-Gen, and SDXL on industry benchmarks GenEval and DPG-Bench, according to information shared by DeepSeek AI.
Image: DeepSeek AI
Its release comes just days after DeepSeek made headlines with its R1 language model, which matched GPT-4’s capabilities while costing just $5 million to develop—sparking a heated debate about the current state of the AI industry.
The Chinese startup’s product has also triggered sector-wide concerns it could upend incumbents and knock the growth trajectory of major chip manufacturer Nvidia, which suffered the largest single-day market cap loss in history on Monday.
DeepSeek’s Janus Pro model uses what the company calls a “novel autoregressive framework” that decouples visual encoding into separate pathways while maintaining a single, unified transformer architecture.
This design allows the model to both analyze images and generate images at 768×768 resolution.
“Janus Pro surpasses previous unified model and matches or exceeds the performance of task-specific models,” DeepSeek claimed in its release documentation. “The simplicity, high flexibility, and effectiveness of Janus Pro make it a strong candidate for next-generation unified multimodal models.”
Unlike with DeepSeek R1, the company didn’t publish a full whitepaper on the model but did release its technical documentation and made the model available for immediate download free of charge—continuing its practice of open-sourcing releases that contrasts sharply with the closed, proprietary approach of U.S. tech giants.
So, what’s our verdict? Well, the model is highly versatile.
However, don’t expect it to replace any of the most specialized models you love. It can generate text, analyze images, and generate photos, but when pitted against models that only do one of those things well, at best, it’s on par.
Testing the model
Note that there is no immediate way to use traditional UIs to run it—Comfy, A1111, Focus, and Draw Things are not compatible with it right now. This means it is a bit impractical to run the model locally and requires going through text commands in a terminal.
However, some Hugginface users have created spaces to try the model. DeepSeek’s official space is not available, so we recommend using NeuroSenko’s free space to try Janus 7b.
Be aware of what you do, as some titles may be misleading. For example, the Space run by AP123 says it runs Janus Pro 7b, but instead runs Janus Pro 1.5b—which may end up making you lose a lot of free time testing the model and getting bad results. Trust us: we know because it happened to us.
Visual understanding
The model is good at visual understanding and can accurately describe the elements in a photo.
It showed a good spatial awareness and the relation between different objects.
It is also more accurate than LlaVa—the most popular open-source vision model—being capable of providing more accurate descriptions of scenes and interacting with the user based on visual prompts.
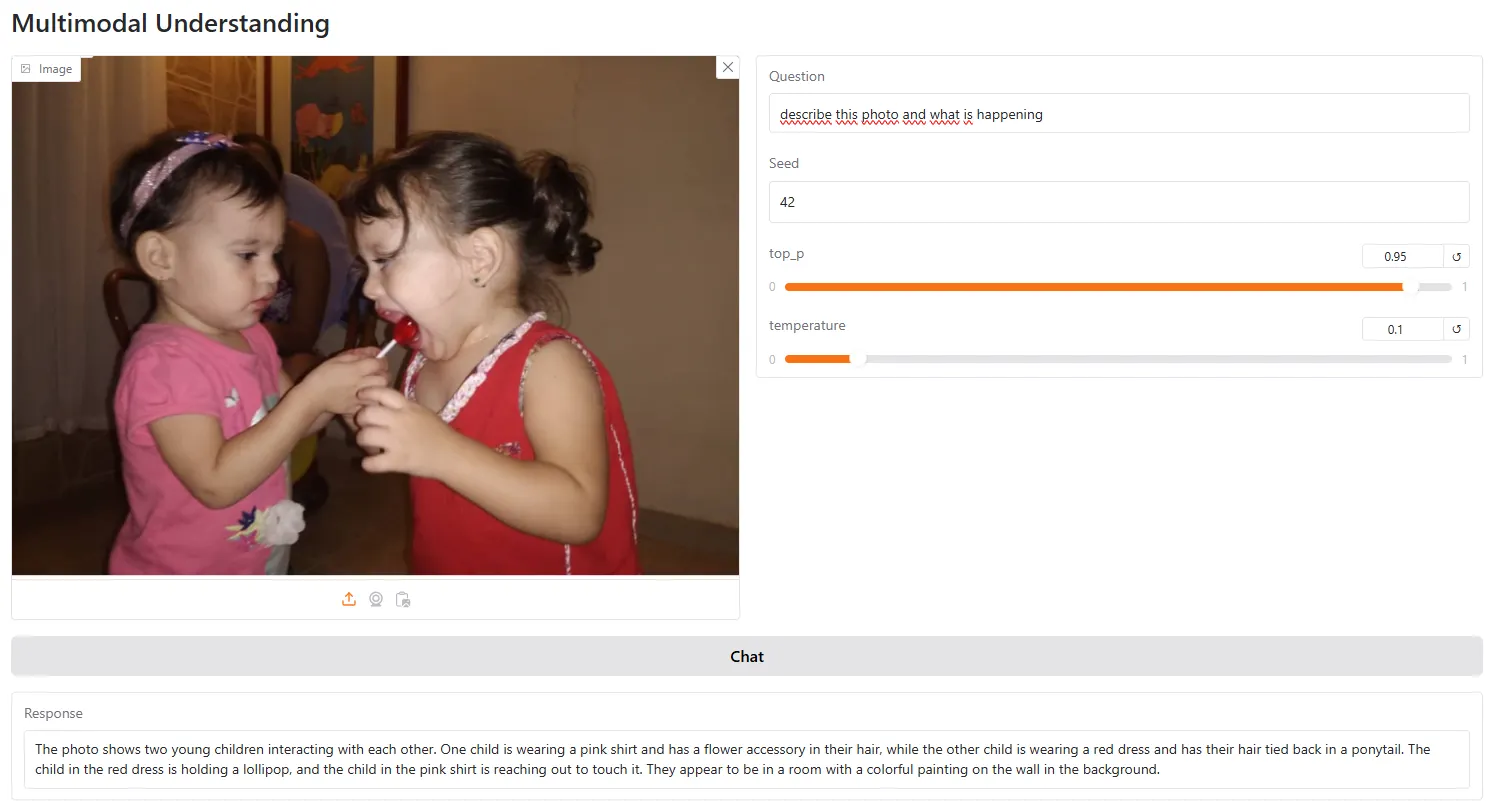
However, it is still not better than GPT Vision, especially for tasks that require logic or some analysis beyond what is obviously being shown in the photo. For example we asked the model to analyze this photo and explain its message

The model replied, “The image appears to be a humorous cartoon depicting a scene where a woman is licking the end of a long red tongue that is attached to a boy.”
It ended its analysis by saying that “the overall tone of the image seems to be lighthearted and playful, possibly suggesting a scenario where the woman is engaging in a mischievous or teasing act.”

In these situations where some reasoning is required beyond a simple description, the model fails most of the time.
On the other hand, ChatGPT, for example, actually understood the meaning behind the image: “This metaphor suggests that the mother’s attitudes, words, or values are directly influencing the child’s actions, particularly in a negative way such as bullying or discrimination,” it concluded—accurately, shall we add.

A league of its own
Image generation appears robust and relatively accurate, though it does require careful prompting to achieve good results.
DeepSeek claims Janus Pro beats SD 1.5, SDXL, and Pixart Alpha, but it’s important to emphasize this must be a comparison against the base, non fine-tuned models.
In other words, the fair comparison is between the worst versions of the models currently available since, arguably, nobody uses a base SD 1.5 for generating art when there are hundreds of fine tunes capable of achieving results that can compete against even state-of-the-art models like Flux or Stable Diffusion 3.5.
So, the generations are not at all impressive in terms of quality, but they do seem better than what SD1.5 or SDXL used to output when they launched.
For example, here is a face-to-face comparison of the images generated by Janus and SDXL for the prompt: A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting, immortal, fluffy, shiny mane, Petals, fairy, highly detailed, photorealistic, cinematic, natural colors.

Janus beats SDXL in understanding the core concept: it could generate a baby fox instead of a mature fox, as in SDXL’s case.
It also understood the photorealistic style better, and the other elements (fluffy, cinematic) were also present.
That said, SDXL generated a crisper image despite not sticking to the prompt. The overall quality is better, the eyes are realistic, and the details are easier to spot.
This pattern was consistent in other generations: good prompt understanding but poor execution, with blurry images that feel outdated considering how good current state-of-the-art image generators are.
However, it’s important to note that Janus is a multimodal LLM capable of generating text conversations, analyzing images, and generating them as well. Flux, SDXL, and the other models aren’t built for those tasks.
So, Janus is far more versatile at its core—just not great at anything when compared to specialized models that excel at one specific task.
Being open-source, Janus’s future as a leader among generative AI enthusiasts will depend on a slew of updates that seeks to improve upon those points.
Edited by Josh Quittner and Sebastian Sinclair
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Source: https://decrypt.co/303061/deepseek-strikes-again-open-source-ai-model-dall-e-3

